Welcome to Matrix Education
To ensure we are showing you the most relevant content, please select your location below.
Select a year to see courses
Select a year to see available courses

Still unsure about linear regressions and bivariate data? Well, don’t fear! We will explain everything you need to know to ace linear regressions.
A worksheet to test your knowledge. 
Free Y12 Maths Advanced Linear Regression Download
Probability and Statistics is extensively used in mathematics, statistics, finance, science, artificial intelligence and many more areas of study.
Surprisingly, the topic that underpins hard probability problems is an area of mathematics called combinatorics (meaning counting!) Indeed, as probabilities are the ratios of the number of ways an event can happen to the total number of possibilities, the step is to develop a theory of counting.
We are going to look at the following NESA syllabus points.
The following Syllabus Outcomes will be addressed in this Subject Guide:
Students only need to be familiar with arithmetic for combinatorics.
Students should already be familiar with the basic concepts of probability. They should also understand basic algebraic techniques and expansion to understand the concepts explored in the following guide.
Bivariate Data is data collected in pairs \( (x, \ y) \) being the results of some experiment or observation.
Here, the variable is called the \( x \) independent variable and the variable \( y \) is called the dependent variable.
For example, \( x \) may be the amount of money invested in TV advertising for a particular business and \( y \) can be the corresponding profit that business earnt for that value of \( x \).
For instance, a data point would mean $2500 was invested in advertising, and $7000 was made in profit.
In Bivariate Data analysis, we aim to see if there is a relationship or an association between the variable \( x \) and \( y \). This relationship will generally be just a trend, and not a deterministic relationship, because the variable \( y \), like profit in the above example, may depend on may other factors not captured by just \( x \).
Now, we will introduce some terminology and tools used to describe bivariate data.
Bivariate data can be visualized using a scatter plot, where the independent variable is placed on the horizontal axis, and the dependent variable is placed on the vertical axis.
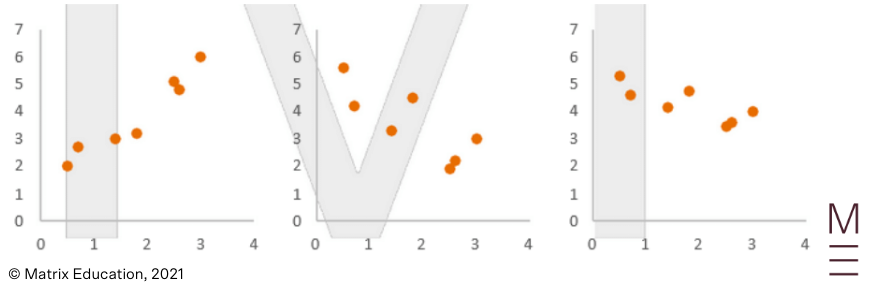
A dataset is linear if the data has a roughly linear trend. For instance, the following plots indicate a linear dataset:
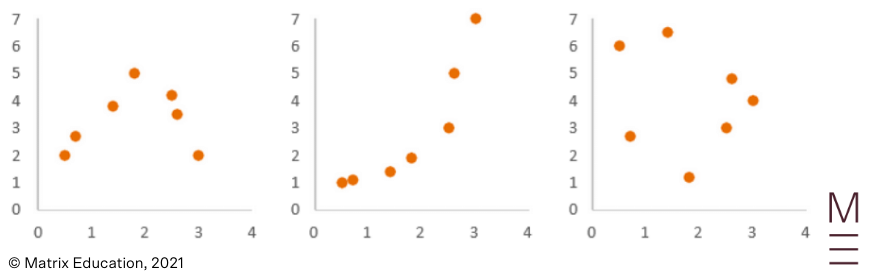
A data set is non-linear if the data does not follow a line shape. Instead, it could have no trend at all, or perhaps a curved/more complicated trend. For instance:
The correlation measures the strength and direction of this linear relationship. We will look at each of these below:
Strength
When there is a linear trend, the strength of association can be of three categories – strong correlation, medium correlation and weak correlation. When there is no linear trend, we say there is no correlation. The strength of correlation is to do with how aligned the data points are.
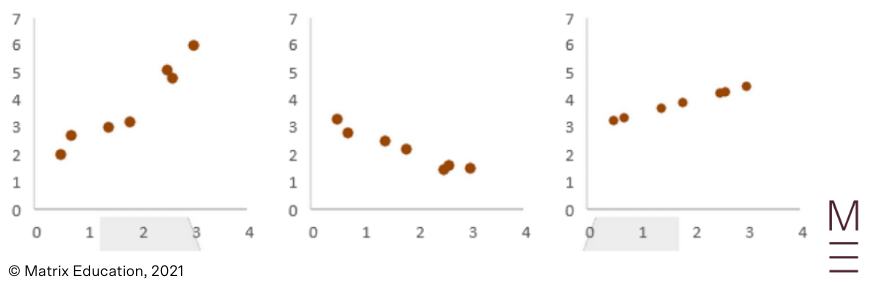
Strong Correlation: The following plots exhibit strong correlation.
Medium Correlation: The following plots exhibit medium correlation.
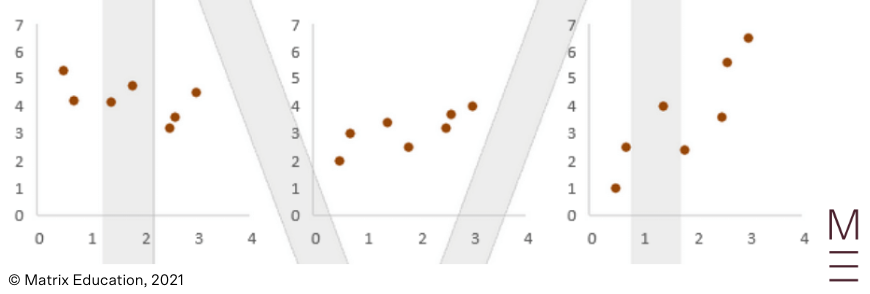
Weak Correlation: The following plots exhibit weak correlation.
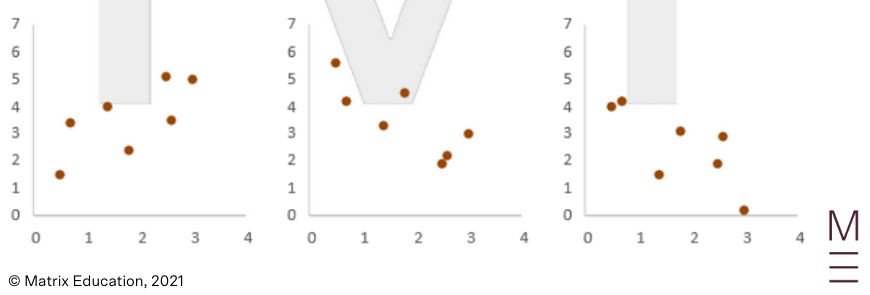
No correlation: We can also have no correlation, meaning the data points show no sign of linearity.
Direction
Correlation can be positive or negative.
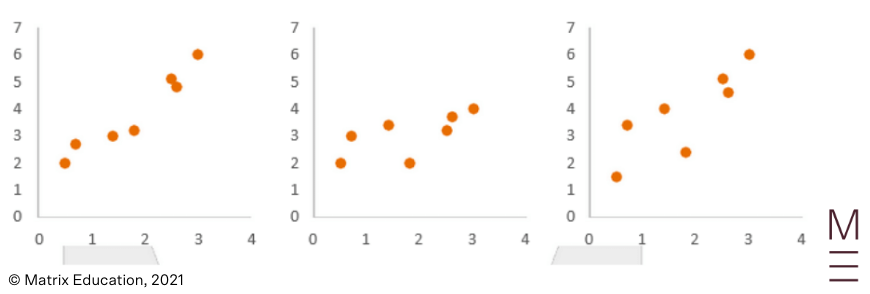
Positive Correlation: The following plots exhibit positive correlation – as \( x \) increases, \( y \) increases.
So far, we have only described correlation qualitatively. However, it is difficult to compare two plots which both might have medium strength positive correlation.
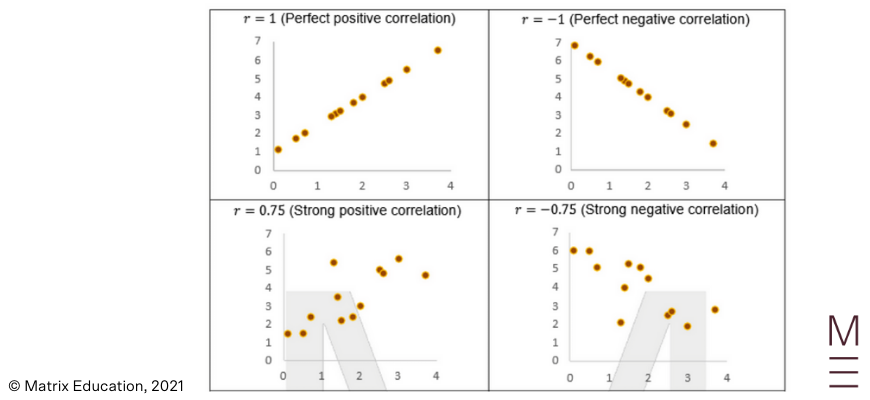
Pearson’s correlation coefficient is a quantitative measure for correlation. It denoted by the letter \( r \) (which is why it is also called Pearson’s \( r \) ) and ranges between -1 and 1.
The magnitude of Pearson’s coefficient relates to the strength of the linear relationship. The sign of Pearson’s coefficient describes the direction of the linear relationship.
The following plots are annotated with how to interpret Pearson’s correlation.
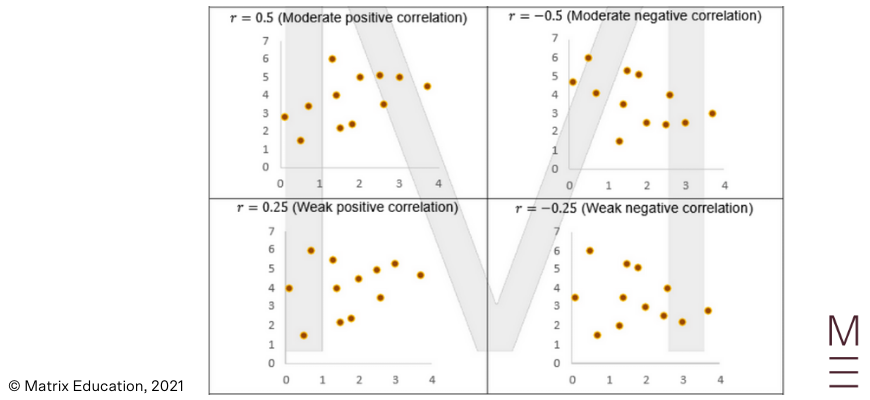
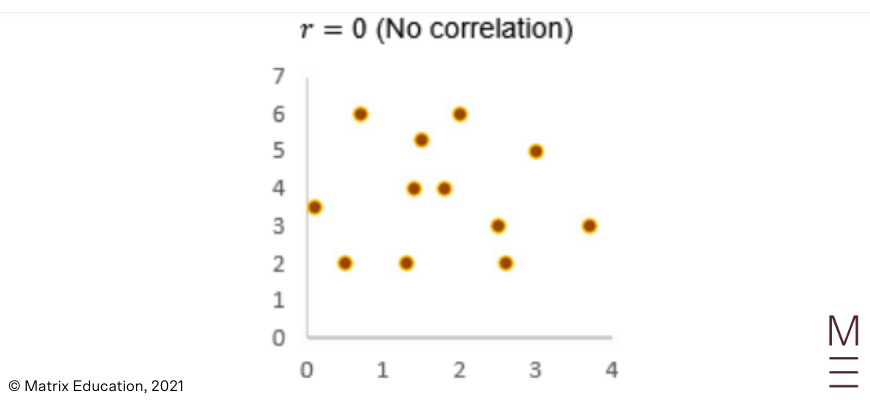 |
As we have seen, while our data on a scatter plot may not be exactly linear, there may be a linear trend. We can describe this linear relationship qualitatively or using Pearson’s Coefficient.
Now, we will actually approximate the data using a line of best fit (also know as the least-squares regression line). A line of best fit aims to best represent the data at hand with a straight line.
When a line of best fit is constructed by a computer or by a calculator, the line drawn will have the shortest vertical distance from the data points as possible.
There are various reasons to use a line of best fit:
Students need to be able to draw an approximate line of best fit. For example, the line of best fit through the below scatter plot is shown:
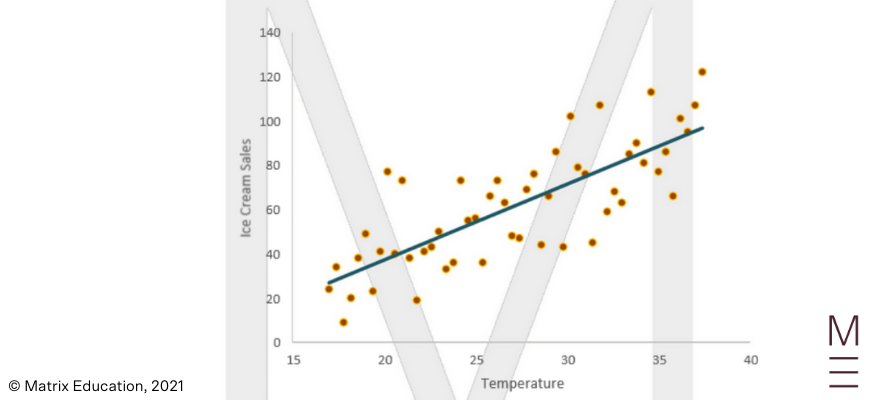
The syllabus requires students to use technology to find
when data is provided. In exams, they can use their calculators to do so.
Steps:
Once the line of best fit is drawn, calculated or provided by the question, it can be used to predict the value of \( y \) at a hypothetical value of \( x \) .
There are two types of prediction:
Here, the range of our data refers to the values between the first point and the last point as you go from left to right.
Note: Extrapolation is prone to error because it assumes the trend in the existing data will continue for values of \( x \) outside of the data available. Unless the data analyst is sure that the linearity of the trend will continue instead of, for example, curving off, extrapolation can produce meaningless data because of the strong assumptions.
The CEO of a company wanted to see the relationship between the number of years that each employee has been working for and their annual salary. The results are displayed in the scatterplot below:
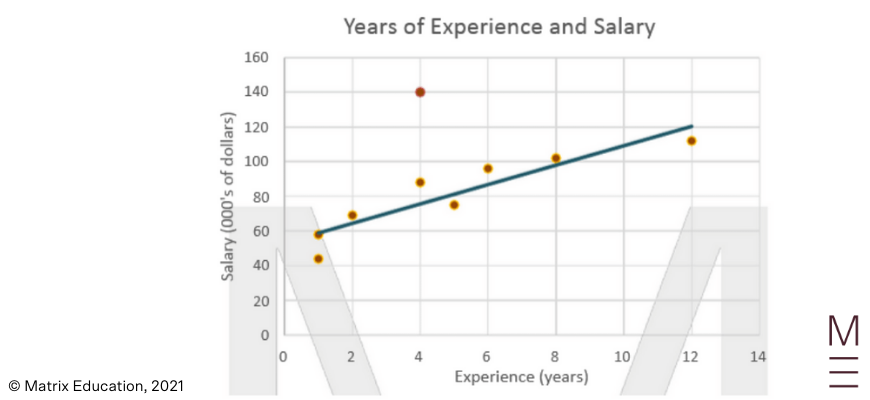
1) Identify any outliers.
2) Estimate the correlation coefficient.
3) What is the equation of the least squares regression line?
4) What is the meaning of the intercept and gradient of this model?
5) Matthew has been working at the company for 10 years. Predict his salary.
1) The point (4, 140) is an outlier, potentially an exceptional employee that is compensated highly for their work despite having less experience than others.
2) 0.9 (The data is fairly linear and positively correlated)
3) \( y = 5.25x + 58 \)
4) The intercept approximates the average salary of an employee with no experience to be around $58,000 while the gradient suggests a $5250 increase in annual salary from a one-year increase in experience.
5) $110,000
Learn Maths Adv from home with Matrix+ Online Course! We will provide you with video theory lessons, access to our comprehensive Maths workbooks mailed to your door, and Q&A Discussion Boards to help you target your questions. Learn more about Matrix+ Online Maths Adv Course now.
© Matrix Education and www.matrix.edu.au, 2025. Unauthorised use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Matrix Education and www.matrix.edu.au with appropriate and specific direction to the original content.